作為人類的一項基本智慧,常識推理是指在日常生活中,人類對所遇到的場景利用常識知識作出推斷的能力。例如:如果小明剛剛吃了一大碗米飯,我們利用常識知識就可以推斷,他現在不餓;如果小明只有五歲,利用常識可以推斷他不能灌籃。Mueller (2005) 將常識推理定義為從世界某個場景中獲取資訊,並利用常識知識或世界的運行規律對該場景的其他方面作出推斷的過程。按照這一定義,基於邏輯方法構建的常識推理系統需要包括三個部分:1) 場景資訊的獲取和表示;2) 常識知識庫;3) 邏輯推理機制。
McCarthy (1959) 在 “Program with common sense” 中最早提出要讓電腦具有智慧,首先要讓電腦程式具有常識知識。例如:我正坐在家裏的辦公桌前,我現在想要去機場,而且我的車也在家。以此為例,場景資訊可以表示為:at (I, desk), at (desk, home), at (car, home);目標可以表示為 at (I, airport)。可以設想,一個機器人要實現去往機場的目標,需要具備以下的基本常識:需要開車去機場而非步行;需要先從桌子的位置進入車內才能啟動車子;啟動車子需要有車鑰匙等等。
要讓電腦具有常識推理能力,首先要將人類的常識置入電腦中。一個自然的問題便是人類具有哪些種類常識(McCarthy 和 Haypes 1969)。按照常識推理主頁 (https://commonsensereasoning.org/) 的分類,常識知識至少包括以下幾類。1) 關於時間、改變、行為和因果的常識;2) 物理和空間常識;3) 法律、生物、醫學、科學推理的常識;4) 關於信念、意圖和情感的心理狀態的常識;5) 社會活動和關係的常識。
確定了常識的種類和表示方法後,下一步面臨的問題是如何表示和獲取常識知識。常識的表示方法見下一節。常識的獲取方法主要有以下三種(Davis 和 Marcus 2015): 1) 專家構造的方式,例如 CYC 知識庫 (Lenat 1995);2) 利用網路挖掘技術從網頁文本中提取相關的常識資訊,例如:KnowItAll 專案 (Etzioni 2004);3) 眾包 (crowdsourcing) 的方式,即通過大量的網路用戶來收集常識知識,例如:ConceptNet 專案 (Speer 2017)。其中專家構造的方式精確度最高,成本也最高;網路挖掘的方式準確度較差,且容易出現不一致的情況;眾包的方式較之網路挖掘方式更為準確,但是並不適用於收集一些基礎領域的常識,例如時間和空間的常識,這是由於一般的用戶無法給出關於這些領域的系統知識。
經過幾十年的努力,人工智慧學界構建了諸多的常識知識庫,例如:WordNet (Fellbaum 2010)、ConceptNet (Speer 2017)、VerbNet (Schuler 2005)、FrameNet (Baker 1998)、Cyc (Lenat 1995)、Knowledge Graph、DBpedia (Lehmann 2015)、YAGO (Suchanek 2007)。這些知識庫從理論基礎到實際的構造方式都有很大的不同。WordNet 最初是基於認知科學理論構建的;VerbNet、FrameNet 是基於語言學理論構建的;Cyc 是基於邏輯學理論構建的;ConceptNet、Knowledge Graph、DBpedia、YAGO 是從具體的工程應用的實際出發來構建的。這些知識庫像 WordNet、VerbNet、FrameNet、Cyc 最初完全人工構建的,後利用一些資訊技術輔助人工構建;Knowledge Graph、DBpedia、YAGO 是利用語義抽取計算自動構建的;ConceptNet 最初是採用眾包的形式收集數據,後又採用資訊處理技術進行結構化。
McCarthy 和 Hayes (1969) 提出了三種對知識表示的充足性的標準:1) 形上學充足的表示是指世界所具有的形式與我們所感興趣的現實的方面無矛盾;2) 認識論上的充足性,即這一表示可以表達人類實際上所具有的知識;3) 啟發性上的充足性,即在解決問題時所採用的推理過程在語言中是可表達的。
儘管學界已經構建了多個常識知識庫,並未解決常識推理問題。一個重要的原因是常識知識的表示往往是不充分的。例如:面對「鱷魚能跨欄嗎」這樣的問題 (Levesque 2014),人類可以通過鱷魚的高度、彈跳能力以及欄杆的高度等常識推斷鱷魚不能跨欄。電腦要實現這一推理,也需要具備這些常識。然而,一般情況下,當我們描述鱷魚的性質時,我們一般不會描述鱷魚的彈跳能力(參見維基百科)[1],但在這一推理問題中,我們則需要鱷魚的彈跳能力這一常識來判定它是否能夠跨欄。由此可以看出,在解決一個具體的常識推理問題時所需的常識知識有時會超出我們對事物自身的一般性認知。而且,在未遇到這個問題時,人們幾乎不太可能想到,需要在常識知識庫中增加「鱷魚的彈跳能力」這樣的常識。
再如:「腳踢到牆上,牆不會動,腳會痛」,「腳踢到礦泉水瓶上,礦泉水瓶會移動,腳不會痛」,這些都屬於常識。因為常識推理不僅僅針對的是對現實世界已經發生或必然發生事情的推理,還包括很多可能場景的推理,例如:「腳踢到泡沫牆」、「腳踢到裝滿冰塊的礦泉水瓶」、「腳踢到打火機」、「腳踢到釘書機」、「腳踢到大狼狗」等場景。這世界上的事物成千上萬,若要將此類的知識全部寫入知識庫,必然造成知識庫的爆炸。
為避免這種情況,一種自然的解決方案是使用模式化的標記法來減少常識知識的數量。例如:使用「踢 X 會導致腳…, X…」這樣的模式來表示上述的常識知識,此時需要考察 X 的性質,例如 X 的品質、密度、硬度、體積、是否可移動性、是否是動物等等,根據 X 的性質來確定所導致的結果如何。這種表示方法要求在表示每種事物時都需要描述此事物的這些性質。這種方法看上去是合理的,但在具體實施時會遇到許多的困難。一方面,很難在較大範疇層面描述這些性質,例如「椅子」這樣的範疇:對於不同種類、材質的椅子,其品質、密度、硬度相差非常大,無法給出統一的描述;另一方面,此處描述的僅僅是「踢」這一個動作,還有諸如「抱」、「拿」、「拎」、「捶」、「摔」等更多的動作,對這些動作的描述需要描述事物其他更多的性質。
常識推理面臨的另一個問題是如何將這些常識應用到具體的推理問題中。當面對一個具體問題時,需要利用常識知識庫中的知識來得到預期的結論。當前一般的常識知識庫都包括幾百萬條常識知識,如何從中挑選出相關的知識參與推理是常識推理面臨的重要挑戰。如果讓所有的知識都參與推理,那會導致計算量非常大,推理效率極低。如果不能把所有相關知識都挑出來,又會導致推理不完全,並因而無法推出期望的結論。
當前人工智慧界有許多關於常識推理的任務,如 Winograd 模式挑戰(Levesque 2011;Levesque 等 2012)、識別文本蘊含(Dagan 等 2009;Dagan 等 2013)、合理選項選擇任務 (Roemmele 2011) 等。在當前這些主流的評測任務上,語言模型系統的表現遠遠優於基於邏輯方法所構建的系統。例如:在 Winograd 模式挑戰中,基於 GPT-3 語言模型的系統的準確率超過了 90%(Brown 等 2020),而基於邏輯方法構造的系統只能處理部分的 Winograd 實例,並且準確率低於 70%(Kocijan 等 2020)。儘管如此,基於語言模型的方法是將兩個備選答案帶入,然後利用語言模型計算兩個句子的生成機率,機率高的即為正確答案,這種方法本質上並非在進行常識推理。Saba (2018) 認為這種數據驅動的方法會嚴重誤導甚至是損害那些真正需要語言理解的領域。
在認知科學中,知識表示是在頭腦中標示有關知識內容與結構的方式,包括感覺、知覺、表像等形式,又包括概念、命題、圖式等形式(史忠植 2008)。在人工智慧領域,科學家嘗試將人類的知識形式化為機器能夠處理的形式,常用的知識表徵方法有:一階邏輯表示、產生式系統、框架表示、語義網路、腳本、概念圖等(Brachman 和 Levesque 2004)。在這些表示方法中,一階邏輯表示顯然是基於邏輯的一種標記法;產生式系統、語義網路在本質上也都與邏輯有著緊密關係。Hayes (1979) 認為框架表示也可以視為一階邏輯的一種變體。
一階邏輯語法
一階邏輯的符號表包括邏輯符號與非邏輯符號,邏輯符號是指具有語言中具有確定意義的符號,而非邏輯符號的意義則是不確定的,在不同的解釋模型下有不同的意義。一階邏輯語言包括四種類型的邏輯符號:
1) 邏輯連接詞和量詞:¬, ∧, ∨, →, ↔, ∃, ∀,其中 ¬ 表示否定,∧ 表示合取,∨ 表示析取,→ 表示蘊涵,↔ 表示等價,∃ 表示「存在…」,∀ 表示「對所有…」。
2) 變項:x1, x2,⋯, xn, ⋯無窮多個符號。
3) 等詞:=
4) 括弧:(, )
一階邏輯的非邏輯符號有以下三種:
1) 常項符號:c1, c2,⋯, cn, ⋯ 無窮多個符號
2) 函數符號:f1, f2,⋯, fn, ⋯無窮多個符號
3) 謂詞符號:P1, P2,⋯, Pn, ⋯無窮多個符號
其中函數符號和謂詞符號有不同的元數,例如:fatherOf 是一個一元函數,加法函數是一個二元函數,Father 是一個一元謂詞,Friend 是一個二元謂詞。
確定了符號表後,可以由這些符號進一步組成更為複雜的運算式,即詞項和公式。詞項指稱某個具體的個體,採用歸納定義的方式定義如下:
公式集可以歸納地定義如下:
一階邏輯語義
一階邏輯語義論通過模型去對一階語言作出解釋。一階語言中邏輯符號的意義是確定的,而非邏輯符號的意義則需要通過模型來解釋。一階語言中的詞項指稱具體的個體,而公式表達的是具有真假的命題。例如:“Mary” 是一個個體常項,按照詞項的定義,它是一個詞項,它指稱的是現實世界中被叫做 “Mary” 的個體。“Happy” 是一個一元謂詞,Mary 是一個詞項,從公式定義可知 “Happy(Mary)” 是一個公式,這一公式表達的是「瑪麗是快樂的」這一命題。要對一階語言進行解釋,需要給出一個關於這個世界的模型,依據這個世界的模型能夠對語言中的各種非邏輯符號作出解釋。
一個模型 M 是一個二元組 <D, η>,其中 D 是一個非空集合,稱為模型的論域;η 是一個映射,將語言中的元素解釋為論域 D 上的個體、函數或關係。
個體常項被解釋為論域中的個體,n 元函數符號被解釋為從 Dn 到 D 上的函數,n 元謂詞被解釋為論域上的 n 元關係。例如:論域 D 表示所有人的集合,“Mary” 是一個個體常項,它被解釋為論域中一個具體的人;“fatherOf” 是一個一元函數,它表示的是從論域 D 到論域 D 的函數,“fatherOf(Mary)” 表示 Mary 的父親;“Friend” 是一個二元謂詞,它表示的是一個 D×D 的子集,所有有朋友關係的人組成的二元組都屬於這個集合,假如 John 和 Mary 是朋友,那麼 <JohnM, MaryM> ∈η (Friend)。為了統一記法,我們使用 cM, fM, PM 來表示非邏輯符號 c, f, P 的解釋。
給定模型後,任何一個不含變項的詞項和公式都可以在此模型中得到解釋。為解釋含有變項的詞項和公式,還需要確定變項的指稱。一個變項指派函數 μ 是一個從個體變項集到論域 D 的函數。給定了變項指派函數後,一階語言符號表中的所有符號都有了確定的意義,按照組合性原則,一階語言其他複合運算式的意義便得以確定。我們稱模型 M 和變項指派函數 μ 組成的二元組為一個解釋 I=<M, μ>。在解釋 I 下,項 t 的指稱可通過如下方式定義:
假設 t1,⋯, tn 是詞項,P 是一個 n 元謂詞,ϕ 和 ψ 是公式,x 是變項,公式的可滿足條件定義如下:
其中解釋 I(a/x) 是使用 a 替換解釋 I 中 x 的解釋所得到的一個新的解釋,二者的唯一區別在於對 x 的賦值可能會不同。⊨ 是一種可滿足關係,I⊨P(t1,⋯, tn) 表示解釋 I 滿足公式 P(t1,⋯, tn),或者 P(t1,⋯, tn) 在解釋 I 下為真。給定任一解釋,我們可以判定一個公式在此解釋下是否為真。例如:給定解釋 I=<M, μ>,其中 M=<D, η>,D={a, b, c}, JohnM=a, MaryM=b, FriendM={<b, c>},考慮公式 Friend(John, Mary) 在此解釋下的真值。按照定義,由於 <JohnM, MaryM> ∉FriendM,因此,Friend(John, Mary) 在此解釋下為假。
知識表示
要使用一階語言表達常識知識,首先需要確定符號表中的常項、函數和謂詞符號。世界中被命名的實體一般是由常項來表達的,被命名的實體一般是指人物、地點、公司等。例如:John、張三、長城、微軟等都是被命名的實體,我們將表達這些實體的詞彙視為個體常項。自然語言中所使用的函數多半是一元的,例如:fatherOf, bestFriendOf 等,這些函數是從論域人到論域人的函數。由於函數要求論域中的每個元素都有對應的值,因此,如果使用 bestFriendOf 函數,意味著每個人有且僅有一個最好的朋友,否則 bestFriendOf 就不是一個函數。自然語言中的謂詞有兩類,一類表達性質或屬性;一類表達關係。例如:一元謂詞 Human 和 Rich 表達的是性質或屬性;二元謂詞 Friend 和 Love 表達的是二元關係。
維特根斯坦在《邏輯哲學論》中提出世界是事實的總和,要描述這個世界,實際上是描述這個世界的事實 (Wittgenstein 1953)。大部分的事實都可以使用原子公式或者原子公式的否定來表達。例如:Happy(John), ¬Happy(Mary), ¬Love(John, cat), John=bestFriendOf(Mary)。有些事實需要使用複雜的一階公式表達,例如:「珠穆朗瑪峰是世界最高峰」被表示為 ∀x(Mountain(x)→Higher(Qomolangma, x))。一階語言還可以用來表達不完全的知識。例如:「Mary 最好的朋友是 John 或者 Thomason」被表達為 John=bestFriendOf(Mary)∨Thomason=bestFriendOf(Mary)
除了對於世界中具體事物相關的事實描述,還有一些規律性或者術語性質的事實描述。例如:「人終有一死」是一個規律,被表示為 ∀x(Human(x)→Mortal(x));單身漢指的是未婚男人,被表示為 ∀x(Bachelor(x)→Man(x)∧Unmarried(x))。Brachman 和 Levesque (2004) 中總結了不相交性、子類型、窮盡性、對稱性、逆關係、類型限制、完全定義等 7 種術語事實的表達。
一階邏輯在知識表示上不受論域的限制,無論何種論域,都可以通過向一階語言中增加相應的常項、函數和謂詞來表達這一論域中的個體和關係。例如:談論考古學相關的知識時,若要表達「漢文帝的霸陵位於西安市白鹿原江村」,首先將其中的專名作為常項加入到符號表中,使用 “Hanwen”、“Baling”、“Xi’an”、“Bailuyuanjiang” 分別表示漢文帝、霸陵、西安市和白鹿原江村;然後將其中的關係詞作為謂詞加入符號表中,此處有兩種關係,一種是漢文帝和霸陵間是一種擁有關係,而霸陵和白鹿原江村、白鹿原江村和西安市是一種位於關係,我們使用 “Possess” 和 “LocatedIn” 分別表示這兩種關係,那麼這句話可以表示為 LocatedIn(Baling, Bailuyuanjiang)∧Possess(Hanwen, Baling)∧LocatedIn(Bailuyuanjiang, Xi'an)。
一階語言的表達力有限,自然語言中的某些成分無法通過一階語言表達。例如:一階語言中僅有存在和全稱量詞,像 「大多數的」、「不少於三分之一」的這樣的量詞無法使用一階語言精確表達。為了克服這種不足,邏輯學家和語言學界提出了廣義量詞理論(Barwise 和 Cooper 1981),通過對一階邏輯進行擴充,來刻畫其它類型量詞的語義。除此之外,一階邏輯也無法精確刻畫自然語言中的模態和時態詞,邏輯學家嘗試在經典一階邏輯中引入模態詞或時態詞,使用邏輯方法來刻畫自然語言中的模態和時態詞的性質 (Manzano 1996)。
產生式系統 (production system) 的概念最早由 Post 於 1943 年所提出的產生式規則得來 (Post 1943),產生式系統是目前專家系統中最主要的知識表示方法之一,同時也是目前人工智慧界應用最為廣泛的知識表示方法。上世紀 70 年代,Newell 開始使用產生式系統來作為邏輯理論家的分支控制結構 (Gugerty 2006),同時,產生式系統也被視為人類問題解決的一種理論模型(Simon 和 Newell 1971)。
產生式系統由三個部分構成:全域資料庫、產生式規則集以及控制程式。從模擬人類資訊處理的角度看,全域資料庫相當於人在一個場景中所獲取的資訊,模擬的是人的短時記憶的內容;產生式規則是模擬人的長時記憶,存儲的是人腦中長期穩定的知識;控制程式則對產生式規則的選用和推理過程進行控制的部分。Davis 和 King (1975) 詳細介紹了產生式系統的起源、發展、結構、特徵、分類。
從知識表示的角度看,產生式系統中的知識主要包括事實知識和規則知識。其中事實知識使用〈對象—特性—取值〉三元組的表示方法。例如:張三的年齡是 23 歲,那麼通過三元組的方式可以表示為 <Zhangsan Age 23>。在有些專家系統中,還會加入置信度來表示可信程度,並使用四元組表示。例如:張三的年齡有八成的機率是 23 歲,可以表示為 <Zhangsan Age 23 0.8>。若要表達一個對象的多個特性,可通過如下方式來表示<對象<屬性 1:值 1 屬性 2:值 2 …>>。例如:張三性別男,年齡 23,籍貫是山東濟南,可以表示為<張三<性別: 男 年齡: 23 籍貫: 山東濟南>>。
產生式規則知識由前件和後件組成,前件表示前提條件,後件表示當這些前提條件為真時,應採取的行為或所得的結論。產生式的表示規則知識的形式為:「IF 前件 THEN 後件」或者「IF 條件 THEN 行動」。例如:雙足無羽動物是人,表示為:IF x 是動物 AND x 有兩足 AND x 無羽 THEN x 是人。
從邏輯的角度看,產生式系統中的事實知識和規則知識的表示都可以視為一階語言表示的變體。例如:<Zhangsan Age 23> 可以表示為 ageOf(Zhangsan)=23。產生式規則知識可以表示為 l1∧⋯∧ln→q,其中 li 表示原子命題或原子命題的否定。例如:規則「IF x 是動物 AND x 有兩足 AND x 無羽 THEN x 是人」可以表示為 ∀x(Animal(x)∧Biped(x)∧Impennate(x)→Human(x))。
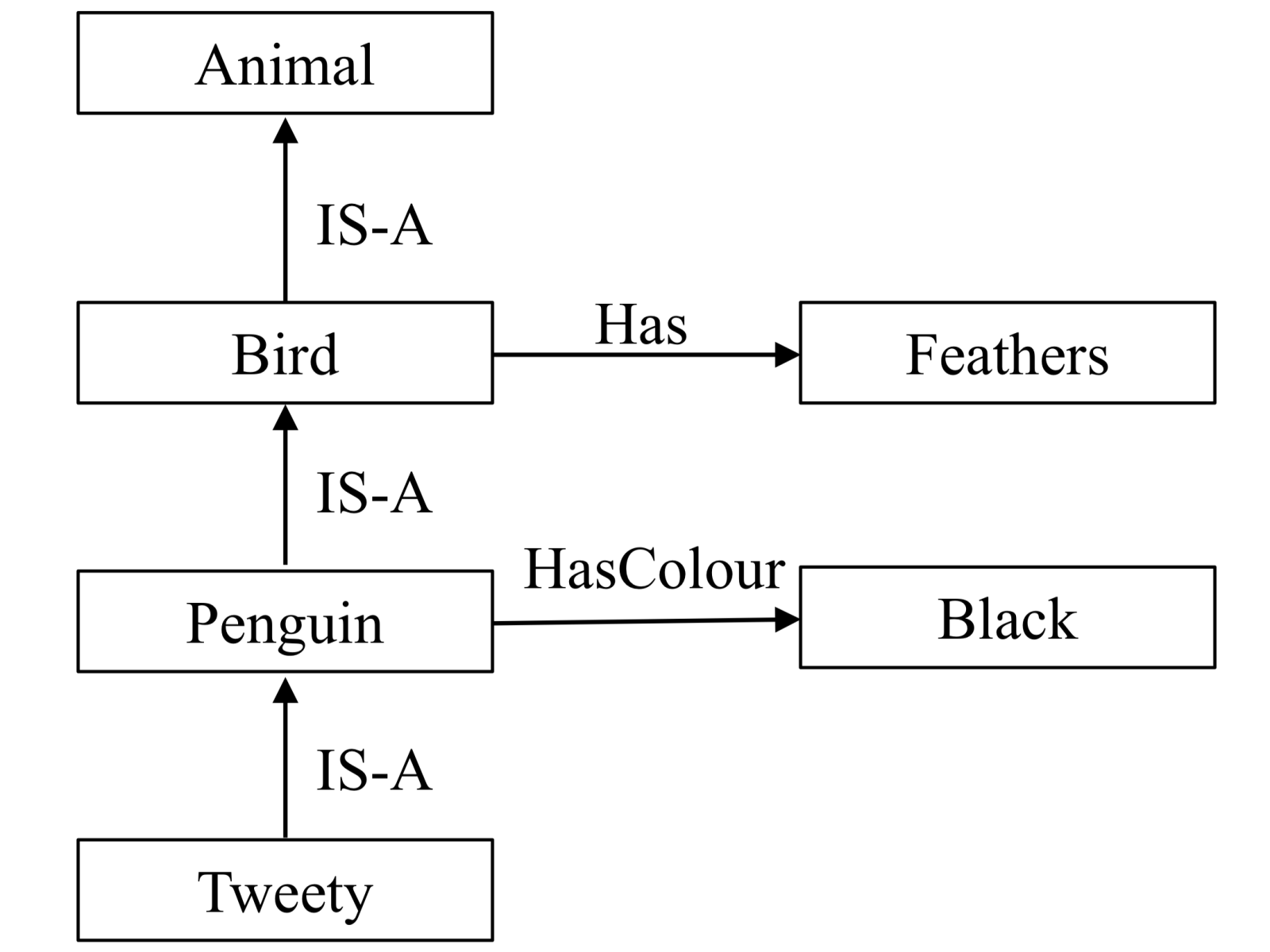
Quillian (1968) 為表示自然語言的語義,提出了語義網路。語義網路由節點和邊組成,節點表示概念和對象,邊表示節點間的關係。語義網路中的 IS-A 邊表示的是一種概念間的種屬關係,例如:鳥是一種動物,鳥和動物兩個概念間有一條 IS-A 的邊。屬性可以沿 IS-A 邊向下繼承。例如:企鵝是鳥,所以企鵝就繼承了鳥的所有特徵。因為鳥有羽毛,所以企鵝也有羽毛。圖 1 展示了一個語義網路的實例。
圖1 語義網路實例
Woods (1975) 和 Brachman (1977) 批評語義網路缺乏形式語義的基礎,在某些情況下會導致歧義性。例如:在圖 1 中,HasColour 有兩種不同的解釋,一種解釋是企鵝身上僅有黑色;一種解釋是企鵝身上至少具有黑色,可能還有其他的顏色。使用一階邏輯公式可以表達這二者的區別。例如:∀x(Penguin(x)∧HasColour(x, y)→Black(y)) 表示企鵝身上只有黑色,∀x(Penguin(x)→HasColour(x, y)∧Black(y)) 表示企鵝身上至少具有黑色。由於一階邏輯推理是不可判定的,邏輯學家提出了一種可判定的邏輯—描述邏輯,來表達這種區別。
描述邏輯語法
描述邏輯的符號表包括邏輯符號和非邏輯符號。以 ALC 系統為例,邏輯符號包括 ⊓, ⊔, ¬, ∀, ∃,非邏輯符號包括概念名稱符號和角色名稱符號,我們使用 NC, NR 分別表示概念名稱集和角色名稱集 (Baader 2007; Baader 2017)。ALC 概念描述為通過如下兩個規則生成的符號串:
例如:Person 和 Male 是兩個概念名稱符號,二者都屬於集合 NC,那麼 Person⊔Male 和 Person⊓Male 也是概念描述。attend 是角色符號,University 是概念符號,那麼 ∀attend.University, ∃attend.University 也是概念描述。
描述邏輯語義
一個解釋是由論域和解釋函數構成的二元組 I=<D,⋅I>,其中 D 是一個非空集合,⋅I 是滿足如下兩個條件的解釋函數 (Baader 2007,Baader 2017):
解釋函數可以進一步被擴展到其他的概念描述:
給定了語義解釋,所有的 ALC 概念描述都可以得到解釋。例如:設定論域為所有實體的集合,PersonI 是所有人的集合,MaleI 是所有雄性的集合,(Person⊓Male)I 是所有男人的集合,(¬Person)I 是所有非人的集合,(∃attend.University)I 是指所有上過大學的人的集合。
語義網路的知識表示方法由於缺乏形式語義,使得其在對屬性邊的解釋時存在歧義。邏輯學家使用描述邏輯作為語義網路的形式語義基礎,並消除上述的歧義。基於描述邏輯構建的知識庫包括兩個部分:術語集 (Terminological Box, Tbox) 和斷言集 (Assertional Box, Abox)。術語集主要包含描述概念層次結構及概念間關係的公理。這些公理都具有 C⊑D 的形式,其中 C 和 D 是兩個概念描述;C≡D 表示 C⊑D 且 D⊑C。斷言集中包含表達個體和概念間關係的公理。這些公理具有 a:C 和 (a, b):r 的形式,其中 a 和 b 為個體,C 為概念,r 為角色。例如:「所有鳥都是動物」表示為 Bird⊑Animal;「人是雙足無羽動物」表示為 Human≡Biped⊓Impennate ⊓Animal;「John 是人」表示為 John: Human;「John 和 Mary 是朋友」表示為 (John, Mary): Friend。
術語集和斷言集中的公理都可以使用一階語言來表達。例如:C⊑D 可以表示為 ∀x(C(x)→D(x));C≡D 可以表示為 ∀x((C(x)→D(x))∧(D(x)→C(x)));a:C 可以表示為 C(a);(a, b):r 可以表示為 r(a, b)。所有的描述邏輯公式都可以使用一階邏輯公式來表達,ALC 邏輯可以翻譯為帶兩個變項的一階邏輯的片段。之所以選擇描述邏輯而非一階邏輯來表示知識,是由於大部分的描述邏輯都是可判定的,而一階邏輯則是不可判定的,而這也就意味著基於描述邏輯的知識表示方法推理會更有效率。例如:ALC 概念描述的可滿足性問題是 PSPACE 完全的 (Baader 2007)。
語義網路中的子概念一般繼承父概念的所有性質。例如:企鵝是鳥,因為鳥有羽毛,所有企鵝也有羽毛。然而並非所有的概念都滿足繼承性,例如:一般認為鳥會飛,儘管企鵝是鳥,但企鵝並不會飛。如果僅從「Tweety 是鳥」和「鳥會飛」兩個前提出發可以推出結論「Tweety 會飛」。當引入新的前提「Tweety 是企鵝」時,已經推出的結論「Tweety會飛」需要被撤回,並得出結論「Tweety 不會飛」。日常生活中的大部分推理都是非單調的,當增加前提時,原先已得出的結論不再成立需要被撤回,這種類型的推理被稱為非單調推理。這種非單調推理現象往往是由於語言中概稱句的使用所引起的,例如:鳥會飛,四川人吃辣等。概稱句是某種意義上的全稱句,但容忍反例(Geurts 1985,周北海 2004)。
經典邏輯中的推理關係是單調的,即令 Γ, Δ 為任意公式集,ϕ 為任意公式,若 Γ⊢ϕ,那麼 Γ∪Δ⊢ϕ。對非單調推理而言,當增加新的前提集 Δ 時,有時需要撤銷結論 ϕ。早期對邏輯主義方法的批評之一便是經典邏輯無法處理非單調推理現象,並因此認為依靠邏輯方法無法模擬人的日常推理能力 (Minsky 1974)。對非單調推理的邏輯刻畫逐漸成為人工智慧領域研究的重要問題之一。
1980 年第 13 期 Artificial Intelligence 上所發表的三篇文章,即 “Circumscription -A Form of Nonmonotonic Reasoning”, “Non-monotonic Logic I” 以及 “A Logic for Default Reasoning” 標誌著非單調邏輯研究領域的形成。這三篇文章對非單調推理給出了不同的形式刻畫方法。除此之外,目前此令領域流行的方法還有封閉世界假設、形式論辯、自認知邏輯、優先語義等方法。有關這些不同形式化方法之間的關係,請見(Imielinski 1987,Konolige 1988,1989,Kraus 等 1990,Lifschitz 1989)。以下僅介紹三種最為重要的方法 (Baader 1999):基於一致性的方法、模態非單調邏輯和優先語義方法。
Reiter (1980) 所提出的缺省邏輯便屬於這一類。在「鳥會飛」的例子中,如果 x 是鳥,且沒有其他的矛盾的資訊,人們一般會推理出 x 會飛,這是一種默認推理 (default reasoning)。默認推理是一種非單調推理,因為當有其他的矛盾資訊出現時,結論需要被撤回。對默認推理的刻畫最關鍵的是如何去表達「沒有其他的矛盾的資訊」。在這一例子中,Reiter 所採取的策略是「如果x是鳥且可以一致地假設x會飛,那麼鳥會飛」。這一推理可以形式化地表示為如下推理規則:
此處 M 表示「可以一致地假設」,即作了這一假設後,不會導致矛盾。 一般化的缺省規則可以表示為如下形式:
其中 α(x), β1(x),⋯, βm(x), w(x) 是一些公式,其中的自由變項都出現在 x=x1,⋯, xn 中。α(x) 是缺省規則的先決條件,w(x) 是其結論。
Reiter 認為對默認推理的刻畫有雙重的任務:一是通過引入缺省規則,能夠提供一種一階邏輯理論擴充的形式定義;二是能夠提供一種證明論過程來判定公式 w(x) 是否可以被相信,即是否存在一個擴充中包含 w(x)。一個缺省理論是一個二元組 (D, W),其中 D 是缺省集,W 是封閉公式集[2] 。一個擴充 E 應該滿足如下三個條件:
1) E 應該包含 W,即 W⊆E
2) E 應該是演繹封閉的,即 ThL(E)=E
3) 假設 α(x):Mβ1(x),⋯, Mβm (x)/w(x) 是一條缺省規則。如果 α(x)∈E 且 ¬β1 (x),⋯, ¬βm(x)∉E,那麼 w(x)∈E。因而,如果相信 α(x),且 β1(x),⋯, βm(x) 也可以被一致地相信,那麼 w(x) 也被相信。
由此,可以進一步通過如下方式來定義擴充:令 Δ=(D, W) 是一個封閉的缺省理論,因此 D 中的每個缺省都具有 α(x):Mβ1 (x),⋯, Mβm(x)/w(x) 的形式,其中 α(x), ¬β1(x),⋯, ¬βm(x) 都是閉公式。對於任意的閉公式集 S⊆L,令 Γ(S) 為滿足如下三條性質的最小集合:
1) W⊆Γ(S)
2) ThL(Γ(S))=Γ(S)
3) 如果 (α(x):Mβ1(x),⋯, Mβm(x)/w(x))∈D 且 α(x)∈Γ(S),且 ¬β1 (x),⋯, ¬βm(x)∉S,則 w(x)∈Γ(S)。
一個閉公式集 E⊆L 是 Δ 的一個擴充若且唯若 Γ(E)=E,即 E 是個操作符 Γ 的一個固定點 (fixed point)。例如:令 Δ=(D, W),其中 D={∶MA/A, :MB/B, :MC/C}, W={B→¬A∧¬C},按照上述定義,這一缺省有兩個擴充,E1=Th(W∪{A, C}),E2=Th(W∪{B})。由此,我們可以看出缺省規則使用順序的不同可以得到不同的結果,如果缺省規則的順序為:MA/A,:MB/B,:MC/C,那麼會得到擴充 E1,若缺省規則的順序為:MB/B, :MA/A, :MC/C,則會得到擴充 E2。這也是缺省邏輯所解決的主要問題—規則衝突問題,當規則應用順序不同,導致結論不同。
有的一階缺省理論沒有擴充。例如:令 Δ=(D, W),其中 D={∶MA/¬A}, W=∅。對於任一集合 S⊆L,若 ¬A∉S,則由定義的性質 3) 可得 ¬A∈Γ(S),由此可得 S≠Γ(S);若 ¬A∈S,則 ¬A∉Γ(S),由此可得 S≠Γ(S)。因此,這一理論沒有擴充。Kautz 和 Selman (1989) 討論了缺省邏輯的複雜度問題,一階缺省理論是否有擴充的問題是不可判定的。
Reiter 藉由對缺省理論進行限制,以保證限制後的缺省理論都有擴充。一個正規的缺省是指具有 α(x):Mw(x)/w(x) 這樣形式的缺省。一個缺省理論 (D, W) 是正規的若且唯若 D 中的每一個缺省都是正規的。按照這一定義 Δ=(D, W),其中 D={∶MA/¬A}, W=∅,這一定義並非是正規的。所有正規的缺省理論都有擴張,而並非所有有擴充的缺省理論都是正規的。Lukaszewicz (1988) 對 Reiter 擴充的定義作了修改,修改後的定義具有兩個性質,一是每個一階理論都有擴充,二是半單調性,即相對於缺省集是單調的。
McDermott 和 Doyle (1980) 所提出的非單調邏輯 I(Non-Monotonic Logic I,簡稱 NMLI),是在經典邏輯基礎上引入了一個模態詞 M,Mp 表示 p 與所有相信的東西一致。下例展示了一個包含模態詞 M 的理論:
1) Bird(Tweety)∧MFly(Tweety)→Fly(Tweety)
2) Bird(Tweety)
3) Penguin(Tweety)→¬Fly(Tweety)
由此理論出發可以證明 Fly(Tweety),但是如果引入公理 Penguin(Tweety),由 3) 可得 ¬Fly(Tweety),此時 Fly(Tweety) 並不與所相信的東西一致,由此可得 MFly(Tweety) 不成立,也就無法得出 Fly(Tweety)。
設 A 是一個一階邏輯理論,S 是一個公式集,p 由 S 中的公式和理論 A 的公理利用規則推出,可以記為 S⊢A p。定義 Th(S)={p:S⊢p},運算元 Th 具有單調性,即
1) A⊆Th(A)
2) 如果 A⊆B,則 Th(A)⊆Th(B)
Th 運算元還具有冪等性 (idempotence),即 Th(Th(A))=Th(A),很顯然任何的經典推理系統都滿足這一特點。同時,冪等性等式也稱為不動點等式,即從一個理論單調推理出的定理集就是運算元 Th 的一個不動點,Th 運算元計算了在單調推理規則下一個公式集的封閉。
直覺上,為了刻畫非單調推理,需要引入如下規則:如果 ⊬A¬p,則 ⊢A Mp。即如果無法推出一個公式的否定,則可以得出這一公式與已有的公式是一致的。然而這樣引入規則會導致迴圈定義,因為如果這是作為一條推理規則引入系統,在這條規則中使用了「推出」,而「推出」的定義又依賴於系統的規則。為了避免這種情況,McDermott 和 Doyle 採用了不動點的定義方式。
首先保留 ⊢ 的定義,即 ⊢ 仍表示單調推演,然後定義運算元 NM。對於任意的一階理論 A 和任意公式集 S⊆L,NMA(S)=Th(A∪AsA(S)),其中 AsA(S) 是從集合 S 得到的假設集,AsA(S)={Mq:q∈L 且 ¬q∉S}-Th(A)。值得注意的是,系統 A 中具有 Mq 形式的定理並不能算作是假設。NMA 以集合 S 作為輸入,輸出的是一個新的集合,這個集合除了包括 Th(A),還包括那些由未被 S 排除的假設和理論 A 所能推出的公式集。定義完 NM 運算元之後,下一步定義運算元 TH。對於任意的一階理論 A,TH(A) 表示由 A 非單調推出的定理集,且 TH(A) 被定義為 NMA 運算元的最小不動點。TH 運算元刻畫了「如果 ⊬A ¬p,則 ⊢A Mp」這一規則,並且避免了迴圈定義的問題。
設理論 T=PC∪{Mp→¬q, Mq→¬p},NMT 運算元有兩個不動點 F1 和 F2,其中 F1 包含 ¬p 但不包含 ¬q,F2 包含 ¬q 但不包含 ¬p。因為 ¬q 不在 F1 中,因此 Mq∈F1,因此 ¬p∈F1。因為 ¬p 不在 F2 中,因此 Mp∈F2,因此 ¬q∈F2。而 F1∪F2 和 F1∩F2 都不是 NMT 的不動點。因為 {¬p, Mq, ¬q, Mp}⊆F1∪F2,由 ¬p, ¬q∈F1∪F2 可得,Mp, Mq∉NMT (F1∪F2),由此可得 NMT (F1∪F2)≠F1∪F2;由於 ¬p, ¬q∉F1∩F2,因此,Mp, Mq∈NMT(F1∩F2),因而,¬p, ¬q∈NMT(F1∩F2),因而 NMT (F1∪F2)≠F1∩F2。
NMLI 使用不動點技術給出了非單調推理的一個刻畫,但是存在如下兩個問題:1) 這一邏輯不能刻畫融貫的一致性概念。例如:對於理論 T=PC∪{Mp→q, ¬q} 和滿足 S⊬T¬p 的集合 S,由 Mp→q∈T 可得 ⊢T¬q→¬Mp,繼而由 ¬q∈T 可得 ¬Mp∈NMT(S)。由於 S⊬T¬p 可得 Mp∈NMT(S),則 NMT(S) 是不一致的。但是若往 S 中增加 ¬p,則 NMT(S) 是一致的。2) NMLI 無法從 M(p∧q) 推出 Mp 和 Mq,然而這一分配律是非常直觀的,即如果 (p∧q) 和所相信的東西是一致的,那麼顯然 p 和 q 和所相信的東西也是一致的。McDermott 和 Doyle (1982) 在非單調邏輯 I 的基礎上提出了非單調邏輯 II,解決了這些問題。
Shoham (1987) 提出了非單調邏輯的一個整體的語義框架,並且限定邏輯、缺省邏輯、非單調邏輯 I 和 II 都適用於這一新的語義框架。邏輯本質上要刻畫的是命題間的語義後承關係,在經典邏輯中,命題 ψ 是 ϕ 的語義後承 ϕ⊨ψ 是指 ψ 在所有 ϕ 為真的模型中都為真,或者說如果 ϕ 在一個模型中為真,那麼 ψ 在這個模型中也必然為真。在這樣的語義後承定義下,增加前提意味著使前提為真的模型數量減少,那麼結論也必然在這些模型中為真。例如:假設 ϕ⊨ψ,使得 ϕ 為真的模型集合為 A,此時增加前提 χ,使得 ϕ∧χ 為真的模型集合為 B,則必然有 B⊆A,由於 ψ 在 A 中模型中為真,因而,ψ 在 B 中模型中為真。在這樣的語義定義下,增加前提並不會撤回結論,因此,經典邏輯是單調的。
為刻畫非單調的推理,Shoham 在模型集中引入了優先關係 (preference relation),使用 M1≺M2 表示 M2 模型比 M1 優先。由此可以定義公式的優先模型。如果 M⊨ϕ,並且不存在 M' 使得 M≺M' 且 M'⊨ϕ,那麼模型 M 優先滿足 ϕ,即 M 是 ϕ 的一個優先模型,記為 M⊨≺ ϕ。由此定義,顯然有如下結論:如果 M⊨≺ ϕ,則 M⊨ϕ,反之未必成立。由此可以定義一種新的語義後承關係,如果對於任一模型 M,如果 M⊨≺ ϕ,則 M⊨ψ,則稱 ϕ 優先衍推 (preferentially entail) ψ,記為 ϕ⊨≺ ψ。
按此方式定義的語義後承關係是非單調的。例如:假設 ϕ⊨≺ ψ,則 ψ 的模型集是 ϕ 的優先模型集的超集合 (superset)。此時引入前提 χ,要使得 ϕ∧χ⊨≺ ψ 成立,要求 ψ 的模型集是 ϕ∧χ 的優先模型集的超集合。在經典邏輯中,ϕ∧χ 的模型都是 ϕ 的模型,因此,若 ψ 的模型集是 ϕ 的模型集的超集合,則 ψ 的模型集是 ϕ∧χ 的模型集的超集合。然而,對於優先模型而言,ϕ∧χ 的優先模型並不一定是 ϕ 的優先模型,因此 ψ 的模型集未必是 ϕ∧χ 的優先模型集的超集合,即 ϕ∧χ⊨≺ ψ 並不一定成立。
從這一角度來看,McCarthy (1980) 所提出的限制 (Circumscription) 邏輯是優先語義框架的一個特例。限制邏輯的基本想法是假設從事實集 A 中所推出的具有性質 P 的對象就是所有具有性質 P 的對象。例如:事實集 A = {Tweety 會飛,Polly 會飛},由此可以推出會飛的對象僅有 Tweety 和 Polly。將一元的性質 P 推廣到多元關係,可以表述為:從事實集 A中所推出的具有關係 P 的 n 元組就是所有具有 P 關係的 n 元組。
設 A 是包含謂詞符號 P(x1,⋯, xn )(簡記為 P(¯x))的一階邏輯句子,A(Φ) 是將 A 中所有 P 的出現都替換為謂詞運算式 Φ 後所得到的結果。A(P) 中謂詞 P 的限制是一個句子模式:
A(Φ)∧∀¯x(Φ(¯x)→P(¯x))→∀¯x(P(¯x)→Φ(¯x))
A(Φ) 表示 Φ 滿足所有 P 所滿足的條件,∀¯x(Φ(¯x)→P(¯x)) 表示滿足 Φ 的 n 元組的集合是滿足 P 的 n 元組集合的子集,∀¯x (P(¯x)→Φ(¯x)) 表示滿足 P 的 n 元組的集合是滿足 Φ 的 n 元組集合的子集。例如:對於句子 CanFly(Polly) ,謂詞 CanFly 的限制表示為如下的方式: Φ(Polly)∧∀x(Φ(x)→CanFly(x))→∀x(CanFly(x)→Φ(x))。令 Φ(x)≡x=Polly,代入之後的結果是 Polly=Polly∧∀x(x=Polly→CanFly(x))→∀x(CanFly(x)→x=Polly)。其中 ∀x(x=Polly→CanFly(x)) 可以簡化為 CanFly(Polly),由於 Polly=Polly和∀x(x=Polly→CanFly(x)) 都成立,因此,可以得到結論 ∀x(CanFly(x)→x=Polly)。即只有 Polly 會飛。然而,當增加前提 CanFly(Tweety) 時,∀x(CanFly(x)→x=Polly) 這一結論需要被撤回。
從語義的角度看,可以使用謂詞 P 的限制來定義模型集上優先關係。M1≺M2 成立,如果 M1, M2 滿足如下條件:
例如:模型 M1= <D1,η1>,其中 D1={Polly}, η1(CanFly)={Polly},模型 M2= <D2, η2>,其中 D2={Polly, Tweety}, η2(CanFly)={Polly, Tweety}。按照 ≺ 的定義可得 M2≺M1。對於句子 CanFly(Polly) 而言,M1 是它的優先模型,即 M1 優先滿足句子 CanFly(Polly)。限制邏輯假設從事實集 A 中所推出的具有性質 P 的對象就是所有具有性質 P 的對象,此處從 CanFly(Polly) 僅能推出 Polly 具有 CanFly 的性質,且優先模型 M1 滿足 η1 (CanFly)={Polly},因此優先模型可以視為對謂詞限制的語義刻畫。
動作和變化的推理是邏輯方法在人工智慧領域的最為典型的應用之一,儘管使用邏輯方法可以在一定程度上刻畫人類關於動作和變化的推理,但同時面臨著知識表示的難題,如框架問題、結果問題和先決條件問題。
關於世界動態變化的推理是常識推理中的一類重要推理問題,世界的動態變化是由於動作 (action) 所引起的,因此,這類推理又被稱為關於動作的推理 (reasoning about action )。例如:小明把書包從地上挪到桌子上,「挪」這個動作會使得書包的位置發生變化。當前,人工智慧學界主要使用情境演算 (situation calculus) 和事件演算 (event calculus) 來刻畫關於動作和變化的推理(McCarthy 1963, 1969;Kowalski 和 Sergot 1986;Sahannahan 1997;Miller 和 Shanahan 2002)。這二者的主要區別在於對世界的處理方式不同。情境演算使用的是分支時間,而事件演算使用的是線性時間 (Mueller 2015);情境演算中時間的推進是依靠主體執行動作,而事件演算中時間流是以一種獨立時間結構來表示 (Miller 2006)。
情境演算是一種描述情境變化和動作推理的形式化方法,情境演算包括三個基本概念:動作、情境和流 (fluent)。動作是引起世界變化的行為;情境是世界在某一時刻的狀態;流是情境相關的屬性。例如:在挪書包的例子中,「挪」是引起書包位置發生變化的動作,記為 a;「挪」這一動作定義了兩種不同的情境,一種是挪動之前的情境 s0,一種是挪動之後的情境 s1;流是對情境屬性的描述,此處,在地上 (OnFloor) 和在桌子上 (OnTable) 都是流,描述的是情境中書包位置的屬性。流可以視為謂詞,情境作為其中的一個論元。例如:OnFloor 和 OnTable 都是二元謂詞,OnFloor(x, s) 表示在情境s中,x 在地上;OnTable(x, s) 表示在情境s中,x 在桌子上。在這一實例中,OnFloor(SchoolBag, s0) 和 OnTable(SchoolBag, s1) 為真;OnFloor(SchoolBag, s1) 和 OnTable(SchoolBag, s0) 為假。
要完整刻畫動作推理,需要以下四種類型的描述:情境的描述、動作執行的前提條件、動作執行的後果、動作執行。有兩種類型的流來描述情境,即關係流 (relational fluents) 和函數流 (functional fluents),關係流表示為 P(x1,⋯, xn, s) 或者 ¬P(x1,⋯,xn,s)。在情境 s下 P(x1,⋯, xn) 為真,表示為 P(x1,⋯, xn, s),否則表示為 ¬P(x1,⋯, xn, s)。函數流表示為 f(x1,⋯, xn, s=v 表示在情境 s 下,f(x1,⋯, xn) 的值是 v。
一個動作要成功執行需要一些前提條件,情境演算使用 Poss(a, s)≡ϕ 在情境 s下要執行動作 a 的前提條件,其中 ϕ 是對前提條件的具體描述。例如:要能夠啟動汽車,需要有車鑰匙、有汽油、電瓶有電這些前提條件。這一描述可以表示為:Poss(StartCar, s)≡HasKey∧HasPetrol∧BatteryCharged。如果一個情境滿足動作執行的前提條件,那麼這個動作就可以執行。情境演算中使用 s' =do(a, s) 表示動作的執行,即情境 s' 是在情境 s 下,執行完動作 a 後的後繼情境。動作的執行會改變當前世界的狀態,情境演算使用 Poss(a, s)→¬F(x1,⋯, xn, do(a, s))來描述如果情境 s 滿足動作 a 執行的條件,那麼執行完動作 a 後,流 F(x1,⋯, xn) 為真或為假。
後的後繼情境。動作的執行會改變當前世界的狀態,情境演算使用 Poss(a, s)→¬F(x1,⋯, xn, do(a, s))來描述如果情境 s 滿足動作 a 執行的條件,那麼執行完動作 a 後,流 F(x1,⋯, xn) 為真或為假。
如上所述,動作推理的刻畫涉及到四種類型公理的表示:情境公理、前提公理、動作結果公理以及後繼狀態公理。這些知識的表示過程中面臨著許多的問題,其中最為重要的是框架問題 (frame problem)、結果問題 (ramification problem)、先決條件問題 (qualification problem) (Miller 2006)。
McCarthy (1969) 最早提出框架問題,McCarthy 將框架類比為 McCarthy (1962) 中的程式狀態向量 (state vector)。一個程式在某一給定時間的狀態向量是程式中各個變項當前賦值的集合。框架相當於由描述情境所需的各個屬性或流的集合。對動作結果的描述實際上是說明哪些流發生了改變,哪些流沒有發生改變。例如:在挪書包的例子中,除了書包的位置發生了變化,其他物品的位置未發生任何變化。描述變化或者沒有發生變化的公式被稱為框架公理。如果有 n 個動作和 m 個流,就需要構造 m*n 條框架公理。這毫無疑問會引起框架公理數量的爆炸。例如:在挪書包的例子中,假設桌子上還有其他 100 個其他不同種類的物品,執行完「挪書包」的動作後,還需要描述其他 100 個物品的未發生改變。若還有「挪杯子」、「挪凳子」等其他 100 個動作,那所需的框架公理數目就是 10000 條。
框架公理最自然的解決方案是僅描述那些發生變化的流,而不描述那些不發生變化的流 (McCarthy 1969)。McDermott (1987) 將這種做法稱為「睡狗」(sleeping dog) 策略。例如:對於挪書包的例子,僅需要描述書包位置的變化 OnTable(SchoolBag, do(MoveSchoolBag, Floor, Table), s0)),而不需要描述其他物品位置的變化。框架問題也是非單調邏輯研究的動機之一。McCarthy (1980) 所提出的限制邏輯可以視為框架問題的一種解決方案。限制邏輯的基本想法是假設從事實集 A 中所推出的具有性質 P 的對象就是所有具有性質 P 的對象。例如:在挪書包的例子中,由於僅有描述書包位置變化的公理,按照限制邏輯的假設,「挪書包」動作的唯一結果就是書包位置的變化,其他位置均不變。
Shoham (1987) 提出了一種方法能夠將限制邏輯轉換為一種基於優先模型的語義理論,因此,限制邏輯也可以視為是一種基於優先模型的語義理論。限制策略 (circumscription policy) 通過如下方式體現:選擇發生最小改變的那些模型作為優先模型。例如:在情境 s 下,執行完動作 do(Move(SchoolBag), s) 後,其優先模型是僅包含書包位置發生變化的那些模型。很顯然,相對於書包的顏色、重量等發生變化的模型,僅位置發生變化的模型應當是優先被選擇的模型,因為一般情況下,挪動書包並不會改變這些屬性。
框架問題的另一種解決方案是將世界的表示和合適的推理規則結合起來,這樣框架公理既不需要明顯地表示出來,也不需要在推理過程中被明顯地運用。在缺省邏輯中,框架公理的表示和使用是通過規則被隱性地表達出來 (Reiter 1980)。例如:挪書包動作相關的框架公理,可以通過如下兩個規則來表達。Shanahan (1997) 對框架問題的產生發展,以及不同的解決方案進行了詳盡的討論。
結果問題涉及到對動作間接結果或附帶效應的描述。例如:將書包從地上挪到桌子上,直接結果是書包的位置發生了變化。如果桌子是塑膠泡沫做的且書包很重,那麼間接的結果是桌子會被壓垮,桌子被壓垮後,書包又落回到地上。間接結果是伴隨或者緊跟著直接結果發生,然而一個動作描述並不能完全地描述這些所有的可能情況,這也就導致了結果問題。結果問題在上世紀 90 年代廣受關注(McCain 和 Turner 1995;Lin 1995;Gustafsson 和 Doherty 1996;Sandewall 1996;Thielscher 1997;Kakas 和 Miller 1997; Denecker 等 1998)。
Thielscher (1997) 認為對於結果問題,一個成功的解決方案需要能夠解決如下兩個問題:1) 能夠提供一種弱化版本的持續律 (law of persistence),對於不受動作直接或者間接影響的世界描述部分保持不變。2) 間接結果一般是由特定領域依賴關係的一般知識得到的,但是從因果的角度看,並非所有的間接結果都符合我們直覺的。Thielscher 所提出的解決方案使用有向關係來表示兩個結果間的關係,並且描述在什麼限制條件下第一個結果會導致第二個結果。
Shanahan (1999) 認為事件演算通過微小的改變就可以處理結果問題。事件演算包括三種基本概念:動作(或事件)、流和時間點。基本的謂詞包括 Initiates、Terminates、Releases、 InitiallyP、InitiallyN、Happens 以及 HoldsAt。Initiates(a, f, t) 表示在時間點 t 執行完動作 a 後,流 f 開始成立;Terminates(a, f, t) 在時間點 t 執行完動作 a 後流 f 不再成立;Release(a, f, t) 表示在時間點 t 執行完動作 a 後流 f 不再受慣性影響;InitiallyP(f) 表示流 f 從時刻 0 開始成立;InitiallyN(f) 表示流 f 從時刻 0 開始不成立;Happens(a, t) 表示動作 a 發生在時刻 t;HoldsAt(f, t) 表示在時刻 t 流 f 成立。
在事件演算中,一種表達動作間接效果的方式是使用狀態限制 (state constraints) 來表達。狀態限制是由謂詞 HoldsAt 來表達,且對時間論元全稱量化的公式。例如:HoldsAt(Comfortable(x), t↔¬HoldsAt(Hungry(x), t)∧¬HoldsAt(Cold(x), t) 是一個狀態限制。在時刻 t,x 感到舒適等價於x是不餓且不冷的。「吃飽」這一動作的直接效果是「不餓」;「穿暖」這一動作的直接結果是不冷。根據狀態限制公式,如果「不餓」且「不冷」,那麼就會感到舒適。「感到舒適」就是動作「吃飽」和「穿暖」的間接效果。除此之外,還可以使用效果限制 (effect constraints) 和因果限制 (causal constraint) 的方式來表達動作的間接效果。這兩種表示方法可以表達狀態限制無法表達的情況。
一個動作的成功執行需要很多的先決條件。例如:要發動汽車,最基本條件是要有車鑰匙、車有汽油、電池有電。這些前提條件缺一不可,有一條不滿足,則無法成功啟動汽車。除了這些基本的條件外,還有一些突發情況,例如:汽車的排氣管被土豆堵住了,此時也無法成功啟動汽車。與此類似地,汽車的排氣管被塑膠袋堵住了, 汽車的塑膠袋被衛生紙堵住了等等,都會導致汽車無法成功啟動。如此一來,導致汽車無法成功啟動的前提條件不勝枚舉,因而,我們幾乎無法羅列所有的動作執行的先決條件,這也被稱為先決條件問題 (qualification problem)。
對於一個智慧體而言,要解決先決條件問題,需要能夠表示動作執行的先決條件,並且在動作執行失敗之後,能夠解釋動作為何失敗,以及如何從失敗中恢復 (Thielscher 2001)。例如:智能體具備前提條件公理:{PressKey, BatteryCharged}Causes EngineRunning 。那麼在按下汽車的啟動按鈕後,汽車並沒有正常啟動,根據這一公理,便可以推斷出電瓶虧電。如果此時儀錶盤上的電池燈亮起,那麼就可以確認這一解釋。在這種情況下,可以採用搭電啟動的方式來啟動汽車,表示為 JumpStart Causes EngineRunning。
對於動作的前提條件,常常不能一次性地將所有的前提條件都羅列出來,因此,在表示動作前提條件時,要能夠容許前提條件的擴充 (Miller 2006)。例如 {PressKey, BatteryCharged} Causes EngineRunning 公理僅列出了汽車啟動的兩個條件,若要將「車子有油」增加為汽車啟動的前提條件,可以不必修改上述公理,而直接增加公理 ¬Petrol Prevents EngineRunning。在 Moduler-E 中,這種公理被稱為「p-命題」(prevents proposition)。這樣表示更接近與人類一般的思維方式,我們在啟動車子時,並非一開始就將所有導致汽車不能啟動的因素都排查一遍。而是在車子不能正常啟動時,再排查原因。車壞了一般會導致車子無法正常啟動,可以表示為 alwaysBroken→¬EngineRunning。這種命題在 Modular-E 中被表示為「a-命題」(always proposition)。除此之外,Modular-E 中還有「c-命題」(cause proposition)、「o-命題」(occurs proposition) 和「h-命題」(holds proposition)。
以上所列出的導致汽車無法正常啟動的因素都是內在性的,這也被稱為內在性的先決條件 (endogenous qualification)。除此之外,還有一些導致動作失敗的原因完全是外在的因素,被稱為外在性的先決條件 (exogenous qualification)。例如:若按下啟動按鈕,汽車沒有啟動,且電池有電,車有油,那可以推斷由於一些不正常的因素導致車子無法正常啟動。要表示這種情況,可以在前提條件中引入 NormalExo 來表示其他所有未表示出來的正常條件。例如:{PressKey, BatteryCharged, Petrol, NormalExo} Causes EngineRunningnormally NormalExo 表示一般情況下所有其他因素都是正常的。當汽車沒有正常啟動時,且所有明確表示的前提條件都滿足時,則可以推出 NormalExo 不成立。
20 世紀 90 年代以前,邏輯主義一直佔據著人工智慧的主流地位。在此之後,硬體市場的潰敗和理論研究的迷茫,使得人工智慧進入第二次寒冬,科學家逐漸意識到邏輯方法的局限性。近年來,隨著機器學習技術,特別是深度學習技術的不斷發展,當前在人工智慧領域的各項任務或挑戰上,機器學習方法相較於邏輯方法具有絕對優勢,比如,常識推理、圖像識別、自然語言處理等領域。由於深度學習模型缺乏複雜推理能力(LeCun 等 2015;Li 2018),且不能直接處理符號,這使其只能處理相對簡單的語言任務,無法應用於複雜的推理和決策任務。相較之下,邏輯方法在處理複雜的推理任務時具有獨特的優勢,特別是在可解釋性、安全性和可控性方面。因此,對於基於邏輯方法的有效老式人工智慧的研究仍具有重要意義,邏輯方法也將在未來 AI 的發展中扮演重要的角色。
蔡自興,徐光祐,2004。《人工智慧及其應用》,清華大學出版社。
史忠植,2008。《認知科學》,中國科學技術大學出版社。
周北海,2004。〈概稱句本質與概念〉,《北京大學學報 》(哲學社會科學版),41(4):20–29。
Baader, F. 1999. Logic-based knowledge representation. In Artificial intelligence today. 13-41.
Baader, Franz, Calvanese, Diego, McGuinness, Deborah, Patel-Schneider, Peter and Nardi, Daniele, 2007. The description logic handbook: Theory, implementation and applications. Cambridge university press.
Baader, F., Horrocks, I., Lutz, C. and Sattler, U., 2017. Introduction to description logic. Cambridge University Press.
Baker, Collin F., Fillmore, Charles J. and Lowe, John B., 1998. The berkeley framenet project. In: Proceedings of the 17th international conference on Computational linguistics. 86–90.
Barwise, J. and Cooper, R., 1981. Generalized quantifiers and natural language. In Philosophy, language, and artificial intelligence. Springer, Dordrecht. 241-301.
Brachman, Ronald J. 1977. What’s in a concept: structural foundations for semantic networks. Int. Journal of Man-Machine Studies, 9(2):127–152.
Brachman, Ronald J. and Levesque, Hector J., 2004. Knowledge Representation and Reasoning. Morgan Kaufmann Publishers.
Brown, Tom, Mann, Benjamin, Ryder, Nick, Subbiah, Melanie, Kaplan, Jared D., Dhariwal, Prafulla, Neelakantan, Arvind, Shyam, Pranav, Sastry, Girish, Askell, Amanda et al., 2020. Language models are few-shot learners. Advances in neural information processing systems, 33: 1877–1901.
Dagan, Ido, Dolan, Bill, Magnini, Bernardo and Roth, Dan, 2009. Recognizing textual entailment: Rational, evaluation and approaches. Natural Language Engineering, 15(4): i–xvii.
Dagan, Ido, Roth, Dan, Sammons, Mark and Zanzotto, Fabio Massimo, 2013. Recognizing textual entailment: Models and applications. Synthesis Lectures on Human Language Technologies, 6(4): 1–220.
Davis, Ernest and Marcus, Gary, 2015. Commonsense reasoning and commonsense knowledge in artificial intelligence. Communications of the ACM, 58(9): 92–103.
Davis, R. and King, J., 1975. An overview of production systems. Technical rept.
Denecker, M., Dupré, D. Theseider and Belleghem, K. Van. 1998. An Inductive Definition Approach to Ramifications, Electronic Transactions on Artificial Intelligence.
Etzioni, O., Cafarella, M., Downey, D., Kok, S., Popescu, A.M., Shaked, T., Soderland, S., Weld, D.S. and Yates, A., 2004. Web-scale information extraction in knowitall: (preliminary results). In Proceedings of the 13th international conference on World Wide Web, 100-110.
Fellbaum, Christiane, 2010. WordNet. In: Theory and applications of ontology: computer applications. Springer, 231–243.
Geurts, B., 1985. Generics. Journal of Semantics, 4(3):247-255.
Gugerty, L., 2006, October. Newell and Simon's logic theorist: Historical background and impact on cognitive modeling. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting. 50(9):880-884.
Gustafsson, J. and Doherty, P. 1996. Embracing Occlusion in Specifying the Indirect Effects of Actions, In Proceedings 1996 Knowledge Representation Conference (KR 96), pp. 87–98.
Hayes, P. J., 1979. The naive physics manifesto. Expert systems in the microelectronic age.
Imielinski, T. 1987. Results on translating defaults to circumscription. Journal of Artificial Intelligence, 32(1):131-146.
Kakas, A. and Miller, R. S. 1997. Reasoning about Actions, Narrative and Ramification. Electronic Transactions on Artificial Intelligence, 1:39–72.
Kocijan, Vid, Lukasiewicz, Thomas, Davis, Ernest, Marcus, Gary and Morgenstern, Leora, 2020. A review of winograd schema challenge datasets and approaches. arXiv preprint arXiv:2004.13831.
Konolige, K. 1988. On the relation between default and autoepistemic logic. Journal of Artaficial Intelligence, 35(3):233-382.
Konolige, K. 1989. On the relation between circumscription and autoepistemic logic. In N.S. Sridharan, editor, Proceedings of the 12 th International Joint Conference on Artificial Intelligence, IJCAI-89, 1213-1218.
Kowalski, R. and Sergot, M. 1986. A logic-based calculus of events. New Generation Computing, 4(1):67-95.
Kraus, S., Lehmann, D., and Magidor, M. 1990. Nonmonotonic reasoning, preferential models and cumulative logics. Journal of Artificial Intelligence, 44(1-2):167-207.
LeCun, Yann, Bengio, Yoshua and Hinton, Geoffrey, 2015. Deep learning. Nature, 521(7553): 436–444.
Lehmann, Jens, Isele, Robert, Jakob, Max, Jentzsch, Anja, Kontokostas, Dimitris, Mendes, Pablo N., Hellmann, Sebastian, Morsey, Mohamed, Van Kleef, Patrick, Auer, Sören et al., 2015. DBpedia–A large-scale, multilingual knowledge base extracted from wikipedia. Semantic web, 6(2): 167–195.
Lenat, Douglas B., 1995. CYC: A large-scale investment in knowledge infrastructure. Communications of the ACM, 38(11): 33–38.
Levesque, H. J., 2014. On our best behaviour. Artificial Intelligence, 212, pp.27-35.
Levesque, Hector J., 2011. The winograd schema challenge. In: Proceedings of the AAAI 2011 Spring Symposium.
Levesque, Hector J., Davis, Ernest and Morgenstern, Leora, 2012. The winograd schema challenge. In: Proceedings of Thirteenth International Conference on the Principles of Knowledge Representation and Reasoning. 552–561.
Li, Hang. 2018. Deep learning for natural language processing: advantages and challenges. National Science Review.
Lifschitz V. 1989. Between circumscription and autoepistemic logic. In R. J. Brachman, cditor, Proceedings of the 1st International Coriference on Principles of Knowledge Representation and Reasoning, 235-244.
Lin, F. 1995. Embracing Causality in Specifying the Indirect Effects of Actions, Proceedings IJCAI 95, 1985–1991.
Łukaszewicz, W. 1988. Considerations on default logic: an alternative approach 1. Computational intelligence, 4(1):1-16.
Manzano, María. 1996. Extensions of First Order Logic. Cambridge University Press.
McCain, N. and Turner, H. 1995. A Causal Theory of Ramifications and Qualifications, Proceedings of IJCAI 95, 1978–1984.
McCarthy, John. 1960. Programs with common sense. Cambridge, MA, USA: RLE and MIT computation center.
McCarthy, J. 1963. Situations, actions, and causal laws. Stanford University, National Technical Information Service.
McCarthy, J. and Hayes, P. J., 1969. Some philosophical problems from the standpoint of artificial intelligence. Reprint 1981. In: Readings in artificial intelligence. Morgan Kaufmann. pp. 431-450.
McCarthy, John, 1980. Circumscription–A form of non-monotonic reasoning. Artificial intelligence, 13(1-2): 27–39.
McCarthy, J. 1993. Towards a mathematical science of computation. In Program Verification, 35-56.
McDermott, D. and Doyle, Jon, 1980. Non-monotonic logic I. Artificial intelligence, 13(1-2): 41–72.
McDermott, D. 1982. Nonmonotonic logic II: Nonmonotonic modal theories. Journal of the ACM, 29(1):33-57.
McDermott, D. 1987. AI, logic, and the frame problem. In The frame problem in artificial intelligence. Morgan Kaufmann, 105-118.
Miller, R. and Shanahan, M. 2002. Some alternative formulations of the event calculus, in computational logic: logic programming and beyond, in Kakas, A. and Kowalski, R. (Eds), Essays in Honour of Robert Kowalski Part 2, Lecture Notes in Artificial Intelligence, 2408(1):452-90.
Miller, R. 2006. Three problems in logic‐based knowledge representation. In Aslib proceedings, 58(1-2):140-151.
Minsky, Marvin, 1974. A framework for representing knowledge.
Moore, R. C., 1995. Logic and representation. Center for the Study of Language (CSLI).
Mueller, Erik T., 2014. Commonsense reasoning: An event calculus based approach. Morgan Kaufmann.
Newell, Allen and Simon, Herbert, 1956. The logic theory machine–A complex information processing system. IRE Transactions on information theory, 2(3): 6179.
Post, Emil L. 1943. Formal Reductions of the General Combinatorial Decision Problem. Journal of Symbolic Logic. 8(1):50-52.
Quillian, M. 1968. Semantic Memory, in M. Minsky (ed.), Semantic Information Processing, 227-270.
Reiter, Raymond, 1980. A logic for default reasoning. Artificial intelligence, 13(1-2):81–132.
Roemmele, Melissa, Bejan, Cosmin Adrian and Gordon, Andrew S., 2011. Choice of Plausible Alternatives: An Evaluation of Commonsense Causal Reasoning. In: Proceedings of AAAI spring symposium: logical formalizations of commonsense reasoning, 90–95.
Russell, Stuart J. and Norvig, Peter, 2021. Artificial intelligence: A modern approach. 4th Edition. Pearson Education Limited.
Saba, Walid S., 2018. A Simple Machine Learning Method for Commonsense Reasoning? A Short Commentary on Trinh & Le (2018). arXiv preprint arXiv:1810.00521.
Sandewall, E. 1996. Assessments of Ramification Methods that Use Static Domain Constraints, Proceedings of 1996 Knowledge Representation Conference (KR 96).
Schuler, Karin Kipper, 2005. Verbnet: A Broad-coverage, Comprehensive Verb Lexicon [phdthesis]. Philadelphia, PA, USA: University of Pennsylvania.
Shanahan, M. 1997. Solving the Frame Problem: A Mathematical Investigation of the Common Sense Law of Inertia, MIT Press.
Shanahan, M. 1999. The ramification problem in the event calculus. In Proceedigns of IJCAI, 140-146.
Shoham, Y. 1987. A semantical approach to nonmonotonic logics. In Readings in nonmonotonic reasoning, 227-250.
Simon, H.A. and Newell, A., 1971. Human problem solving: The state of the theory in 1970. American psychologist, 26(2), p.145.
Speer, Robyn, Chin, Joshua and Havasi, Catherine, 2017. Conceptnet 5.5: An open multilingual graph of general knowledge. In: Proceedings of 31st AAAI conference on artificial intelligence. 4444–4451.
Suchanek, Fabian M., Kasneci, Gjergji and Weikum, Gerhard, 2007. Yago: A core of semantic knowledge. In: Proceedings of the 16th international conference on World Wide Web. 697–706.
Thielscher, M. 1997. Ramification and Causality. Artificial Intelligence, 89:317–364.
Thielscher, M. 2001. The qualification problem: A solution to the problem of anomalous models. Artificial Intelligence, 131(1-2):1-37.
Wittgenstein, Ludwig, 1953. Philosophical investigations. Basil Blackwell.
Woods, William A. 1975. What's in a link: Foundations for semantic networks. In D. G. Bobrow and A. M. Collins, editors, Representation and Understanding: Studies in Cognitive Science, 35–82. Academic Press.

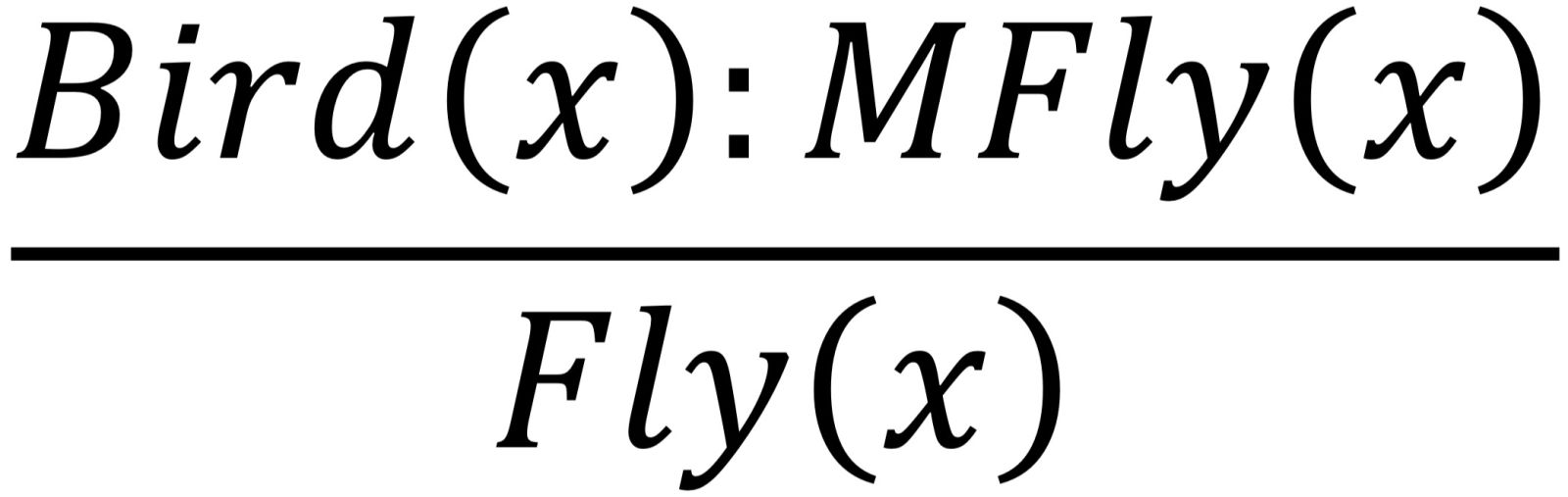
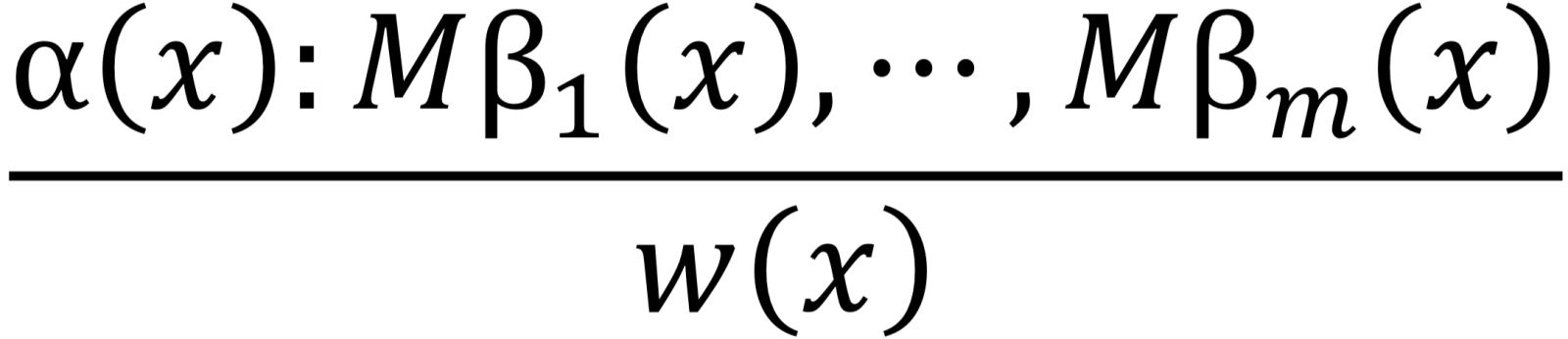
.jpg)